Unicode, UTF8, UTF16, UTF32, ... et tutti quanti
Parfois, lorsqu'on lit un texte, les caractères que l'on voit s'afficher à l'écran ne sont pas ceux escomptés. Soit la personne qui a écrit le texte était saoûl, soit il y a un problème d'encodage de caractère.
Ça c'est le départ de ma réflexion. À cela s'ajoute la magie des caractères accentués que l'on parvient à générer depuis quelques années (les plus jeunes comprendront que l'on n'y parvenait pas jadis) et des questions que posent mes étudiants pour savoir si « Java c'est de l'UTF-8 ou de l'UTF-16 parce que vous nous dites que c'est de l'Unicode ».
— Argh ! Que de vilains mots qu'il faut éclaircir.

Au commencement les ordinateurs ne « comprennent » qu'un seul jeu de caractères (charset) 1 assez limité (avec le recul post 2000).
Dans les années soixante, c'est la norme ASCII (American Standard Code for Information Interchange) qui prévaut et qui comporte 128 codes. ASCII est codé sur 7 bits. Dans ce codage, il n'est pas possible de coder les caractères accentués (ni majuscules, ni minuscules) ce qui deviendra très vite insuffisant. Nous sommes fin des années soixante et « pour ce prix là, on conserve sa machine à écrire ».
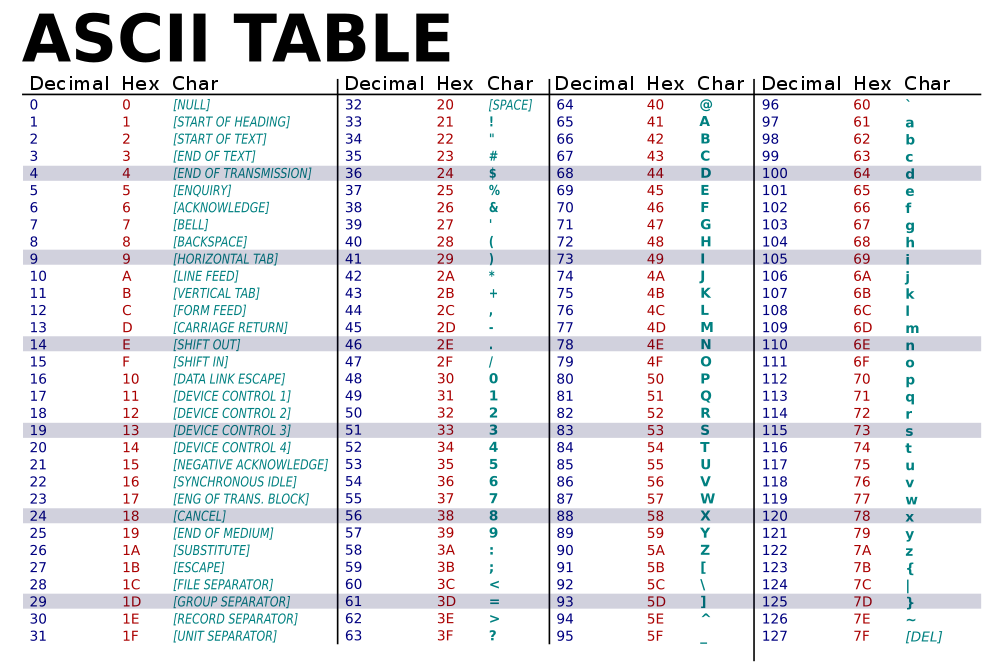
La première évolution vient de l'ISO qui propose des jeux de caractères étendus et différents en fonction de la locale(région, localisation) choisie. On pourra choisir, en Belgique, d'avoir en plus des caractères accentués (en minuscule) et des caractères tels que;œ, &, Œ, æ voire €.
Les caractères ISO8859-1 (petit nom Latin 1 ou Europe occidentale), ISO8859-15 (petit nom Latin-9), … font leur apparition, ils sont codés sur 8 bits. C'est déjà beaucoup mieux mais je serai obligé de choisir si ma machine comprend le jeu de caractères ISO8859-1 (autre petit nom us-US) ou bien ISO8859-15 (autre petit nom fr-FR ou fr-BE) … ce qui se traduira parfois par des dialectes différents (Windows-1252 par exemple) suivant que je travaille avec une machine Linux ou Windows :-(
Bref!
Aujourd'hui, on peut se permettre d'utiliser plusieurs bytes pour coder ses caractères et l'on veut que les applications soient portables et ne soient plus dépendantes de la locale (la région ou simplement le choix de la langue) dans laquelle on les utilise. Il faut trouver un codage des caractères qui soit un surensemble reprenant les caractères existants dans toutes les langues.
La réponse c'est l'Unicode.
Unicode provides a unique number for every character,
no matter what the platform,
no matter what the program,
no matter what the language.
Voilà, c'est facile, Unicode est la réponse universelle et magique au problème de codage de caractères. Un langage, un système, un programme qui comprend l'unicode permettra de coder en utilisant n'importe quel caractère ... Petite pause vers un exemple de code en Java, utilisant des caractères inhabituels.
— D'accord. Mais Unicode, c'est 2 octets ou 3 ou plus?
En fait, au départ, Unicode était codé sur 16 bits mais dans sa version 2, c'est plutôt sur 21 bits.
The Unicode Standard encodes characters in the range U+0000,U+10FFFF, which is roughly a 21-bit code space.
(Unicode.org)
Comme certaines machines ont une architecture 32 bits et d'autres une architectures 64 bits. Comme certains sont big endian et d'autre little endian, représenter un grand nombre (simplement plus grand que 65535) peut se faire de différentes manières. On parlera alors de la façon de coder ces caractères.
Unicode fournit un code (unique) à chaque caractère et UTF-8, UTF-16 ou UTF-32 fournissent une manière de représenter ces codes en termes de bytes.
Wikipédia nous dit,
Le terme codage de caractères est parfois confondu avec la façon dont les caractères sont représentés par une certaine séquence de bits, ce qui implique une forme de codage où le code entier est converti en plusieurs codets (c'est-à-dire des valeurs codées) entiers qui facilitent le stockage dans un système qui gère les données par groupe de bits de taille fixe.
Par exemple, les entiers plus grands que 65535 ne peuvent pas être représentés sur 16 bits, c'est pourquoi le codage UTF-16 représente ces grands entiers comme des couples d'entiers inférieurs à 65536 et qui ne sont pas associés à des caractères (par exemple, 10000 - en hexadécimal - devient D800 DC00).
Ce plan de codage convertit alors les valeurs de ces codes en une suite de bits et ce en prenant garde à un certain nombre de contraintes comme la dépendance vis-à-vis de la plateforme sur l'ordre final des octets (par exemple, D800 DC00 devient 00 D8 00 DC sur une architecture Intel x86).
Un jeu de caractères ou page de code abrège ce procédé en associant directement aux caractères abstraits des séquences de bits spécifiques.
L'Unicode Technical Report #17 explique cette terminologie en profondeur et fournit davantage d'exemples.
Et l'on trouve sur le site de référence d'unicode,
UTF-8 is popular for HTML and similar protocols. UTF-8 is a way of transforming all Unicode characters into a variable length encoding of bytes.
It has the advantages that the Unicode characters corresponding to the familiar ASCII set have the same byte values as ASCII, and that Unicode characters transformed into UTF-8 can be used with much existing software without extensive software rewrites.
En UTF-8 le nombre de bytes utilisés varie de 1 à 4. Les caractères correspondant au codage ASCII sont codés sur 1 byte (les 7 bits ASCII sont précédés d'un bit nul)2. Les autres caractères sont codées sur 2,3 ou 4 bytes et les bits de poid fort précisent le nombre de bytes utilisés pour coder le caractère.
UTF-16 is popular in many environments that need to balance efficient access to characters with economical use of storage. It is reasonably compact and all the heavily used characters fit into a single 16-bit code unit, while all other characters are accessible via pairs of 16-bit code units.
En UTF-16 les caractères sont codés sur 16 ou 32 bits, 2 ou 4 bytes. De manière simple si le code représente une valeur ne dépassant pas 16 bits, le caractère est codé sur 16 bits sinon il sera codé sur 32 bits (le codage et le décodage se faisant en big endian).
UTF-16 en détail sur Wikipédia
UTF-32 is popular where memory space is no concern, but fixed width, single code unit access to characters is desired. Each Unicode character is encoded in a single 32-bit code unit when using UTF-32.
Unicode.org
En UTF-32, c'est simple … et « cher ». Chaque code unicode d'un caractère est codé sur 32 bits … toujours. Comme 32 bits suffisent, le mapping est immédiat.
UTF-32 en détail sur Wikipédia (en)
— Et Java?
— Java utilise l'Unicode ... et le mappage UTF-16 (source Unicode.org).
Pour ce qui est de la représentation des char, Java n'autorise que les caractères compris entre U+0000 et U+FFFF, ce qui correspond bien à la taille d'un char à savoir 2 bytes (et UTF-16 code ces caractères là sur 2 bytes).
Character literals can only represent UTF-16 code units (§3.1), i.e., they are limited to values from \u0000 to \uffff. Supplementary characters must be represented either as a surrogate pair within a char sequence, or as an integer, depending on the API they are used with. A character literal is always of type char.
Extrait de Java language spécifications p27 (61 page du PDF)
Allons un peu plus avant dans la lecture de Java Langage Specifications en ce qui concerne l'Unicode, genre vers la page 13 (48 du pdf).
Dans ses premières versions, Unicode code ses caractères sur 16 bits (à savoir\u0000à\uFFFF) et tout va bien. Java décide d'utiliser le codage UTF-16 et utilise 16 bits pour représenter ses caractères.
Par la suite (dans ses versions 2.1), Unicode accroit le nombre de caractères qu'il peut représenter et utilise donc une plus grande plage de code u+0000 à u+10FFFF.
Pour ce qui est des String, Java utilise des caratères pour les représenter. Lorsqu'un caractère est un caractère de base (codé sur 16 bits), Java utilise un char et lorsque c'est un caractère étendu, Java utilisera deux char. En terme de code unicode, il faut utiliser deux séquences d'échappement.
Prenons le caractère3 « clé de sol » U+1D11E. Pour pouvoir le représenter dans une chaine Java (pour rappel, je ne peux pas le stocker dans un char), je dois faire la petite manipulation décrite chez Wikipédia
- retirer la valeur
0x10000
0xD11E - convertir en binaire et séparer les 10 bits de poid faible et les 10 bits de poid fort
0000110100 0100011110 - ajouter
0XD800aux bits de poid ford
0xD800 + 0x34 = 0xD834 - ajouter
0xDC00aux bits de poid faible
0xDC00 + 0x11E = 0xDD1E
la clé de sol sera représentable en Java par
String s = "\uD834\uDD1E";
Ceci dit; lorsque l'on regarde les tables Unicode, on constate qu'il y a déjà pas mal (65000) caractères de base … et ce n'est donc pas « facile » d'effectuer des tests avec des caractères étendus qui s'affichent dans mes terminaux …
En espérant que ceci vous aura éclairé.
Sources / crédits
- Wikipédia Jeu de caractères
- Wikipédia, Unicode
- Wikipédia ISO 8859-1
- Wikipédia ISO 8859-15
- Wikipédia Big Enddian
- Unicode, unicode.org
- Unicode, unicode.org FAQ
La documentation Java de la classe Character
- Crédit photo chez DeviantArt par Cedarbird
-
Un Jeu de caractères est une association entre un caractère et un nombre permettant de le représenter. On associe par exemple la valeur 65 à la lettre A majuscule. ↩
-
Et UTF-8 est compatible avec les texte ASCII. Ce qui veut dire qu'avec une machine en UTF-8, je peux lire des texte codés en ASCII (ouf) … ce qui ne sera pas le cas pour le Latin9 :-( Je devrai les traiter à grands coups de
iconv. ↩ -
Je ne peux pas représenter ce caractère ici (je ne sais pas très bien comment faire) … mais bien dans une console linux. ↩


{kind=link}